Principles of the reliability pillar
Building a reliable application in the cloud is different from traditional application development. While historically you may have purchased levels of redundant higher-end hardware to minimize the chance of an entire application platform failing, in the cloud, we acknowledge up front that failures will happen. Instead of trying to prevent failures altogether, the goal is to minimize the effects of a single failing component.
Kyndryl Cloud Uplift on Azure general architecture
Here is a high-level look at the Kyndryl Cloud Uplift on Azure general architecture.
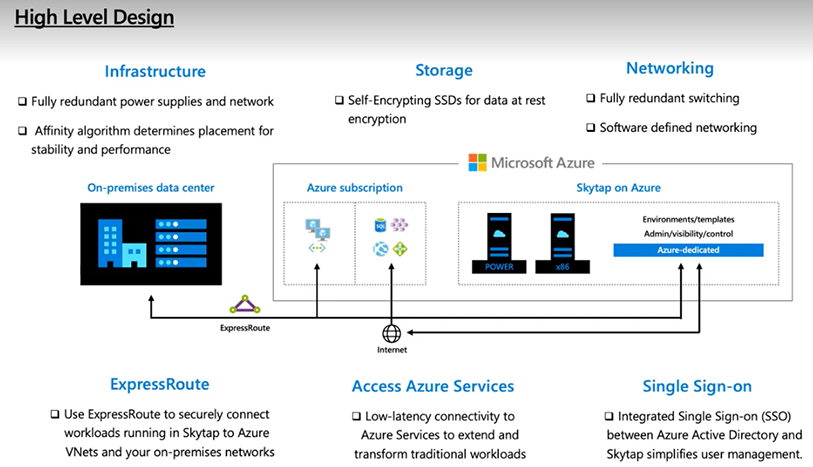
- Define and test availability and recovery targets – Availability targets, such as Service Level Agreements (SLAs) and Service Level Objectives (SLOs), and recovery targets, such as Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs), should be defined and tested to ensure reliability aligns with business requirements.
- Design environments to be resistant to failures – Resilient environment architectures should be designed to recover gracefully from failures in alignment with defined reliability targets.
- Ensure required capacity and services are available in targeted regions – Microsoft Azure services and capacity can vary by region, so it’s important to understand if targeted regions offer required capabilities.
- Plan for disaster recovery – Disaster recovery is the process of restoring application functionality in the wake of a catastrophic failure. It might be acceptable for some applications to be unavailable or partially available with reduced functionality for a period of time, while other applications may not be able to tolerate reduced functionality.
- Ensure networking and connectivity meets reliability requirements – Identifying and mitigating potential network bottlenecks or points-of-failure supports a reliable and scalable foundation over which resilient application components can communicate.
- Allow for reliability in scalability and performance – Resilient applications should be able to automatically scale in response to changing load to maintain application availability and meet performance requirements.
- Address security-related risks – Identifying and addressing security-related risks helps to minimize application downtime and data loss caused by unexpected security exposures.
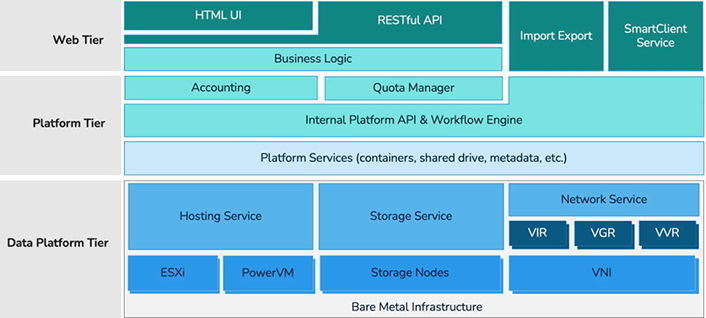
Kyndryl Cloud Uplift service layers
Kyndryl Cloud Uplift is composed of three service layer tiers as depicted below:
- Data Platform Tier – includes Bare Metal infrastructure, hosting service, storage service and network service.
- Platform Tier – includes business logic, accounting, quote manager, internal API and workflow engine and platform services (containers, shared drive, metadata, etc.)
- Web Tier – includes HTML UI, RESTful API, Import Export and SmartClient Service
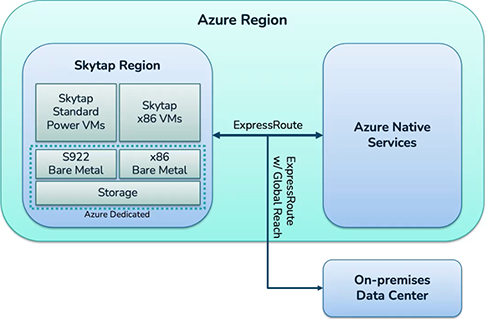
Kyndryl Cloud Uplift on Azure: Microsoft Azure region, Kyndryl Cloud Uplift region and connection to Microsoft Azure native services
Within a given Microsoft Azure region, Kyndryl Cloud Uplift standard Power VMs and x86 VMs and Microsoft Azure-dedicated S922 and x86 bare metal and storage are connected via ExpressRoute to Microsoft Azure native services.
Kyndryl Cloud Uplift discovery and migration – support and limits
The following section outlines Kyndryl Cloud Uplift on Azure support and limits for IBM i and AIX.
Kyndryl Cloud Uplift service limits
High-Level considerations for migration to Kyndryl Cloud Uplift on Azure
Migration to Kyndryl Cloud Uplift on Azure can be migrated via a hot or cold/warm migration.
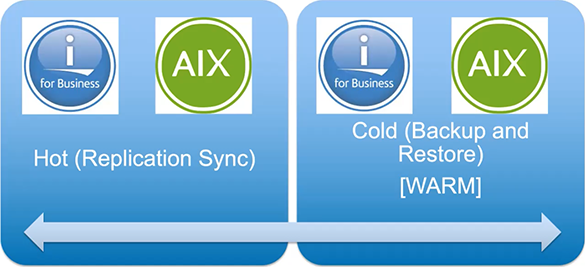
Definitions
RTO – Downtime of services, applications, and infrastructure for business continuity. For example, the amount of time it takes to get back up and running in the event of a disaster or outage.
RPO – Frequency of data backup. For example, the amount of time in which data may be lost.
The two numbers above, combined with contingencies such as distance, amount of data rate change, and available bandwidth will determine whether to employ a High Availability tool or a Disaster Recovery tool.
This is very similar to a warm versus hot migration, and the same tools may be utilized.

Next steps
The sections below in this guide can help the strategy required for the organizational change management required to consistently ensure strong reliability.
These are the disciplines we group in the Reliability Pillar:
| Operational excellence disciplines | Description |
|---|---|
| Migration | The following section provides an overview of Kyndryl Cloud Uplift on Azure architecture and is used as a lens to assess the reliability of an environment deployed in Kyndryl Cloud Uplift. |
| Protection | In the cloud, we acknowledge up front that failures will happen. Instead of trying to prevent failures altogether, the goal is to minimize the effects of a single failing component by keeping your data safe; in this situation, RPO is more critical than RTO. |
| Disaster Recovery | Disaster recovery is the process of restoring application functionality in the wake of a catastrophic loss. A comprehensive disaster recovery solution that can restore data quickly and completely is required to meet low RPO and RTO thresholds. |
| High Availability | Avoiding down time and keeping your critical applications and data online—a high availability solution is required for high RPO and RTO. |